


Introducing Flyte: A Cloud Native Machine Learning and Data Processing Platform


By: Allyson Gale and Ketan Umare
This article was originally published on the Lyft Engineering blog on January 7th, 2020.
Today Lyft is excited to announce the open-sourcing of Flyte, a structured programming and distributed processing platform for highly concurrent, scalable, and maintainable workflows. Flyte has been serving production model training and data processing at Lyft for over three years now, becoming the de-facto platform for teams like Pricing, Locations, Estimated Time of Arrivals (ETA), Mapping, Self-Driving (L5), and more. In fact, Flyte manages over 7,000 unique workflows at Lyft, totaling over 100,000 executions every month, 1 million tasks, and 10 million containers. In this post, we’ll introduce you to Flyte, overview the types of problems it solves, and provide examples for how to leverage it for your machine learning and data processing needs.
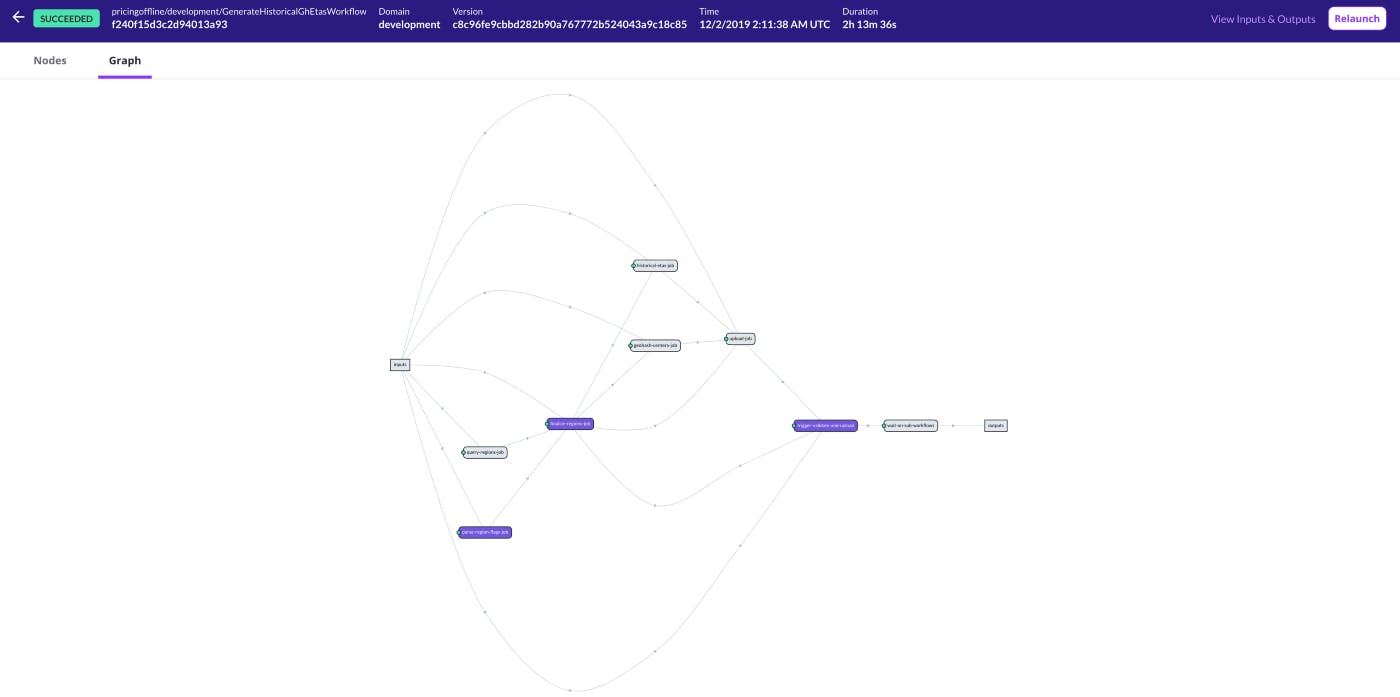 Figure 1. One of many Pricing workflows at Lyft, visualized in the Flyte UI. This workflow was created by Tim Wang on the Rider Pricing team
Figure 1. One of many Pricing workflows at Lyft, visualized in the Flyte UI. This workflow was created by Tim Wang on the Rider Pricing team
The problems Flyte solves
With data now being a primary asset for companies, executing large-scale compute jobs is critical to the business, but problematic from an operational standpoint. Scaling, monitoring, and managing compute clusters becomes a burden on each product team, slowing down iteration and subsequently product innovation. Moreover, these workflows often have complex data dependencies. Without platform abstraction, dependency management becomes untenable and makes collaboration and reuse across teams impossible.
Flyte’s mission is to increase development velocity for machine learning and data processing by abstracting this overhead. We make reliable, scalable, orchestrated compute a solved problem, allowing teams to focus on business logic rather than machines. Furthermore, we enable sharing and reuse across tenants so a problem only needs to be solved once. This is increasingly important as the lines between data and machine learning converge, including the roles of those who work on them.
To give you a better idea of how Flyte makes all this easy, here’s an overview of some of our key features:
Hosted, multi-tenant, and serverless
Flyte frees you from wrangling infrastructure, allowing you to concentrate on business problems rather than machines. As a multi-tenant service, you work in your own, isolated repo and deploy and scale without affecting the rest of the platform. Your code is versioned, containerized with its dependencies, and every execution is reproducible.
Parameters, data lineage, and caching
All Flyte tasks and workflows have strongly typed inputs and outputs. This makes it possible to parameterize your workflows, have rich data lineage, and use cached versions of pre-computed artifacts. If, for example, you’re doing hyperparameter optimization, you can easily invoke different parameters with each run. Additionally, if the run invokes a task that was already computed from a previous execution, Flyte will smartly use the cached output, saving both time and money.
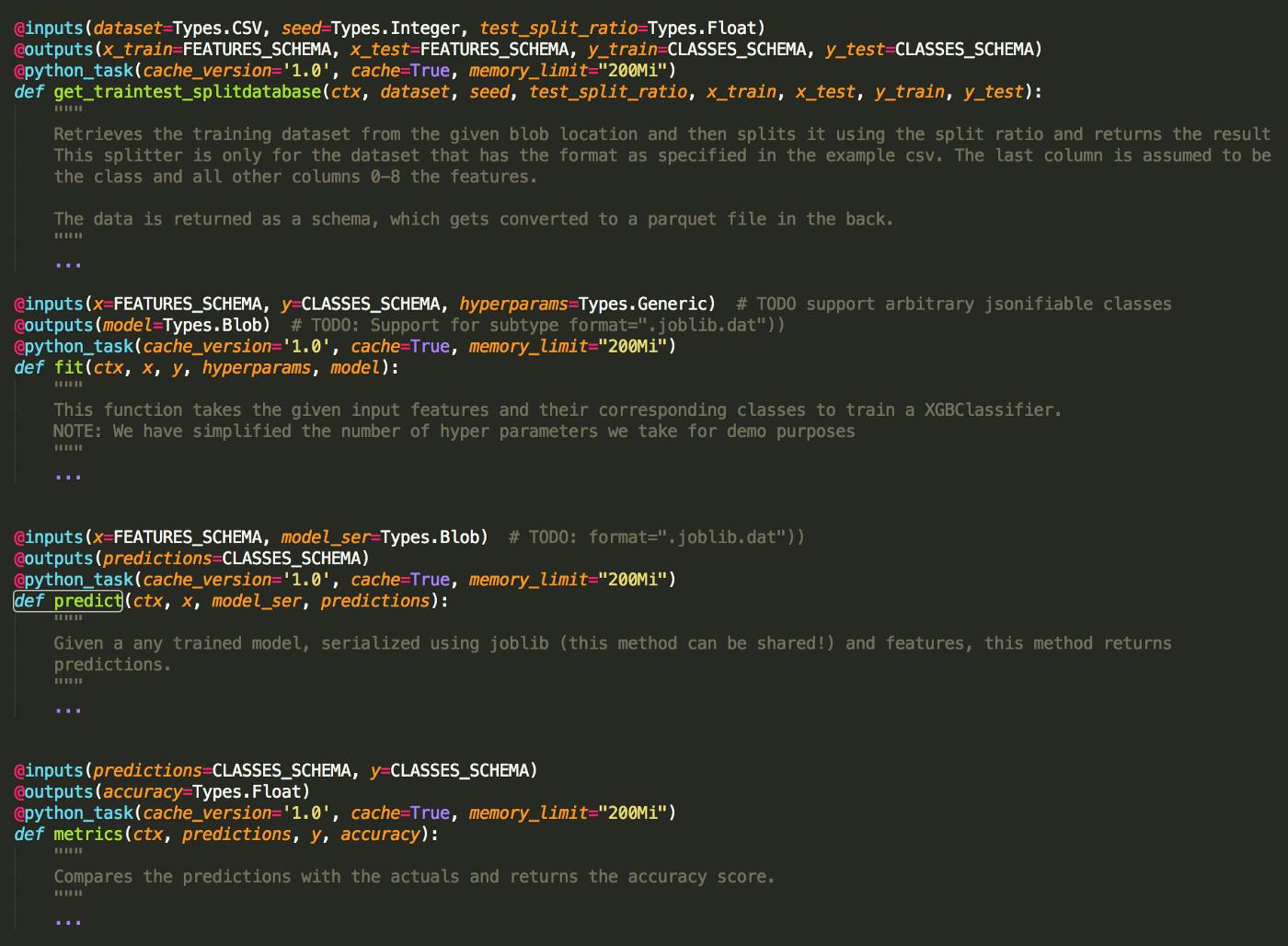 Figure 2. Example: Declaring Tasks with FlyteKit
Figure 2. Example: Declaring Tasks with FlyteKit
In the example above, we train an XGBoost model using the dataset provided here. The machine learning pipeline is constructed in Python and consist of the following four tasks, which align with a typical machine learning journey:
- Data preparation and test validation splits
- Model training
- Model validation and scoring
- Computing metrics
Note how each task is parameterized and strongly typed, making it easy to try different variants and use them in combination with other tasks. Additionally, each of these tasks can be arbitrarily complex. With large datasets, for example, Spark is more preferable for data preparation and validation. Model training, however, can be done on a simple model coded in Python. Lastly, notice how we’re able to mark tasks as cacheable, which can drastically speed up runs and save money.
Below, we combine these tasks to create a Workflow (or “pipeline”). The Workflow links the tasks together and passes data between them using a Python-based domain-specific language (DSL).
 Figure 3. Example: Declaring a Workflow in FlyteKit
Figure 3. Example: Declaring a Workflow in FlyteKit
Versioned, reproducible, and shareable
Every entity in Flyte is immutable, with every change explicitly captured as a new version. This makes it easy and efficient for you to iterate, experiment and roll back your workflows. Furthermore, Flyte enables you to share these versioned tasks across workflows, speeding up your dev cycle by avoiding repetitive work across individuals and teams.
Extensible, modular, and flexible
Workflows are often composed of heterogeneous steps. One step, for example, might use Spark to prepare data, while the next uses this data to train a deep learning model. Each step can be written in a different language and utilize different frameworks. Flyte supports heterogeneity by having container images bound to a task.
By extension, Flyte tasks can be arbitrarily complex. They can be anything from a single container execution to a remote query in a hive cluster, to a distributed Spark execution. We also recognize that the best task for the job might be hosted elsewhere, so task extensibility can be leveraged to tie single-point solutions into Flyte and thus into your infrastructure. Specifically, we have two ways of extending tasks:
FlyteKit extensions: Allow contributors to provide rapid integrations with new services or systems.
Backend plugins: When fine-grained control is desirable on the execution semantics of a task, Flyte provides backend plugins. These can be used to create and manage Kubernetes resources, including CRDs like Spark-on-k8s, or any remote system like Amazon Sagemaker, Qubole, BigQuery, and more.
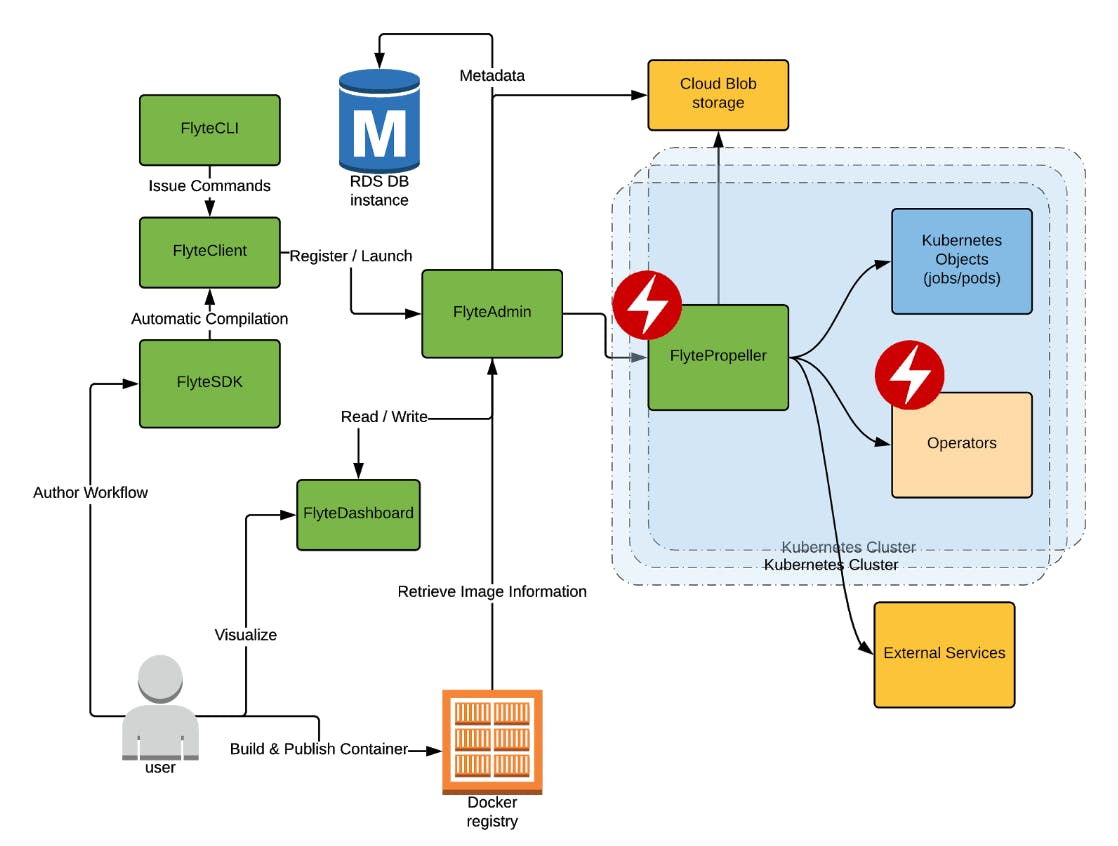 Figure 4. A high-level overview of Flyte’s architecture
Figure 4. A high-level overview of Flyte’s architecture
In conclusion
Flyte is built to power and accelerate machine learning and data orchestration at the scale required by modern products, companies, and applications. Together, Lyft and Flyte have grown to see the massive advantage a modern processing platform provides, and we hope that in open sourcing Flyte you too can reap the benefits. Learn more, get involved, and try it out by visiting www.flyte.org and checking out our Github.