




MapReduce is a prominent terminology in the Big Data vocabulary owing to the ease of handling large datasets with the “map” and “reduce” operations. A conventional map-reduce job consists of two phases: one, it performs filtering and sorting of the data chunks, and the other, it collects and processes the outputs generated.
Consider a scenario wherein you want to perform hyperparameter optimization. In such a case, you want to train your model on multiple combinations of hyperparameters to finalize the combination that outperforms the others. Put simply, this job has to parallelize the executions of the hyperparameter combinations (map) and later filter the best accuracy that could be generated (reduce).
A map task in Flyte intends to implement the task mentioned above. It is primarily more inclined towards the “map” operation.
Referring to Dynamic Workflows in Flyte blog before proceeding with this piece can help deepen your understanding of the differences between a dynamic workflow and map task; however, it isn’t mandatory.
Introduction
A map task handles multiple inputs at runtime. It runs through a single collection of inputs and is useful when several inputs must run through the same code logic.
Unlike a dynamic workflow, a map task runs a task over a list of inputs without creating additional nodes in the DAG, providing valuable performance gains, meaning a map task lets you run your tasks spanning multiple inputs within a single node.
When to Use Map Tasks?
- When there’s hyperparameter optimization in place (multiple sets of hyperparameters to a single task)
- When multiple batches of data need to be processed at a time
- When a simple map-reduce pipeline needs to be built
- When there is a large number of runs that use identical code logic, but different data
Map Task vs. Dynamic Workflow
| Map Task | Dynamic Workflow |
| A map task is statically defined. | A dynamic workflow is dynamically constructed. |
| A map task is purely a task. | A dynamic workflow is a workflow compiled at run time. |
| A single Flyte workflow node can house all the map tasks | Multiple nodes house every task within a dynamic workflow. |
| A map task can accept one task with a single list of inputs that can generate a single list as an output. | A dynamic workflow has no restrictions as such; it can accept any number of inputs and run through any task (interestingly, this could be a map task!). |
A map task’s logic can be achieved using a for loop in a dynamic workflow, however, that would be inefficient if there are lots of mapped jobs involved.
A map task internally uses a compression algorithm (bitsets) to handle every Flyte workflow node’s metadata, which would have otherwise been in the order of 100s of bytes.
We encourage you to use a map task when you want to handle large data parallel workloads!
Usage Example
A map task in Flyte runs across a list of inputs, which ought to be specified using the Python list class. The function you want to call your map task on has to be decorated with the @task decorator, and itself has to conform to a signature with one input and, at most, one output.
At run time, the map task will run for every value. If TaskMetadata or Resources is specified in the map task using overrides, it is applied to every input instance or mapped job.
Here’s an example that “spins up data augmentation of images in parallel using a map task”.
Let’s first import the libraries.
"""
Install the following libraries before running the model.
* pip install tensorflow==2.5.0
* pip install pillow
* pip install simple_image_download
* pip install scipy
"""
import itertools
import os
import typing
import flytekit
from flytekit import Resources, TaskMetadata, map_task, task, workflow
from flytekit.types.file import FlyteFile
from simple_image_download import simple_image_download
from tensorflow.keras.preprocessing.image import (
ImageDataGenerator,
img_to_array,
load_img,
)
Next, we define a task that returns the URLs of five random images based on the given query from Google images.
FlyteFile automatically downloads the remote images to the local drive.
@task(limits=Resources(mem="600Mi"))
def fetch_urls(query: str) -> typing.List[FlyteFile]:
"""Fetch URLs of images from Google"""
response = simple_image_download.simple_image_download
return response().urls(query, 5)
We define a task that generates new images given an image. Memoization (caching) is enabled for every mapped task. The task, in the end, stores the augmented images in a common directory, which we segregate and return as a list of FlyteFiles.
@task(limits=Resources(mem="1000Mi"), cache=True, cache_version="1.0")
def data_augment(image: FlyteFile) -> typing.List[FlyteFile]:
"""Apply data generator onto the images to perform data augmentation"""
datagen = ImageDataGenerator(
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode="nearest",
)
img = load_img(image) # this is a PIL image
x = img_to_array(img) # this is a Numpy array with shape (3, 150, 150)
x = x.reshape((1,) + x.shape) # this is a Numpy array with shape (1, 3, 150, 150)
ctx = flytekit.current_context()
preview_dir = os.path.join(ctx.working_directory, "preview")
os.makedirs(preview_dir, exist_ok=True)
"""the .flow() command below generates batches of randomly transformed images
and saves the results to the `preview/` directory"""
i = 0
for _ in datagen.flow(
x,
batch_size=1,
save_to_dir=preview_dir,
save_prefix=f"{os.path.basename(image).rsplit('.')[0]}",
save_format="jpeg",
):
i += 1
if i > 2:
break # otherwise the generator would loop indefinitely
return [
os.path.join(preview_dir, x)
for x in os.listdir(preview_dir)
if f"{os.path.basename(image).rsplit('.')[0]}" in x
]
We define a coalesce task to convert the list of lists to a single list.
@task(limits=Resources(mem="600Mi"))
def coalesce(
augmented_list: typing.List[typing.List[FlyteFile]],
) -> typing.List[FlyteFile]:
return list(itertools.chain.from_iterable(augmented_list))
Finally, we define a workflow that spins up the data_augment task using the map_task. A map task here helps in triggering the jobs for the list of images in hand within one node. In resource-constrained cases (when the total number of resources is less than the aggregate required for concurrent execution), Flyte will automatically queue up the execution and schedule as and when resources are available.
@workflow
def wf(query: str) -> typing.List[FlyteFile]:
"""
A workflow to call the concerned tasks
This returns a list of augmented images per image
"""
list_images = fetch_urls(query=query)
"""
The map task will be retired once
"""
result = map_task(
data_augment,
metadata=TaskMetadata(retries=1),
)(image=list_images)
return coalesce(augmented_list=result)
if __name__ == "__main__":
wf(query="car")
You can also define a map-specific attribute called min_success_ratio. It determines the minimum fraction of the total jobs which can complete successfully before terminating the task and marking it as successful.
On running this, the output will be a list of files that consist of the augmented images.
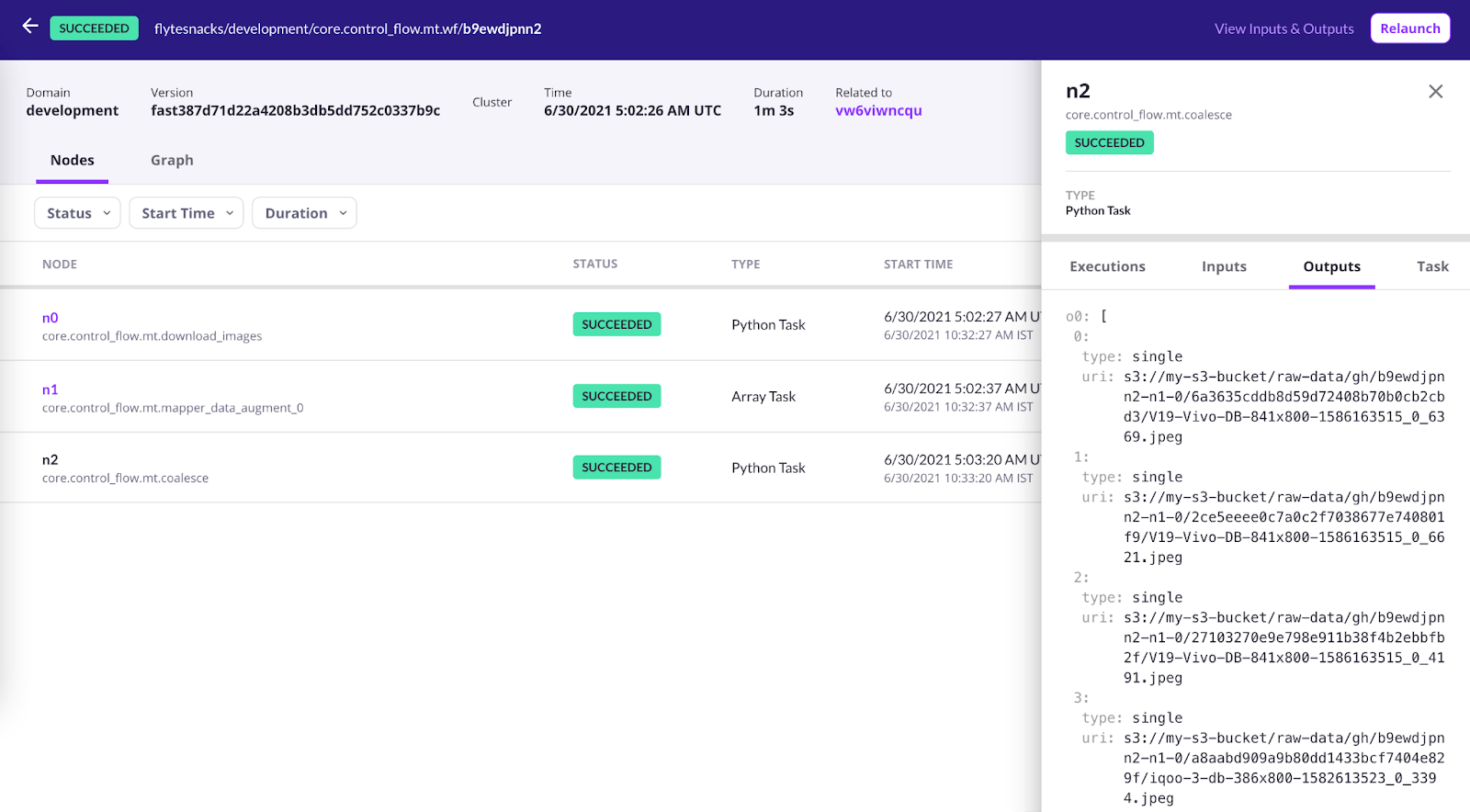 Output generated on running the map task code within the sandbox. We’ve got about fifteen images in total (three per image).
Output generated on running the map task code within the sandbox. We’ve got about fifteen images in total (three per image).
Here’s an animation depicting the data flow through Flyte’s entities for the above code:
List of future improvements (coming soon!):
- Concurrency control
- Auto batching: Intelligently batch larger workloads onto the same pods
Reference: Keras Blog
Cover Image Credits: Photo by Parrish Freeman on Unsplash