#workflow
Read more stories on Hashnode
Articles with this tag
This article was originally published on the Lyft Engineering blog on March 25th, 2022. Introduction In a data-driven company like Lyft, data is the...
This blog is with reference to a talk titled “Efficient Data Parallel Distributed Training with Flyte, Spark & Horovod”, presented by Katrina Rogan...
MapReduce is a prominent terminology in the Big Data vocabulary owing to the ease of handling large datasets with the “map” and “reduce” operations. A...
By: Max Hoffman (Software Engineer at Dolthub) Dolt and Flyte joined forces to build two data integrations. Dolt is a SQL database that supports Git...
By: Jake Neyer (Software Engineer at Striveworks) At Striveworks, we are building a one-of-a-kind data science platform by integrating the building...
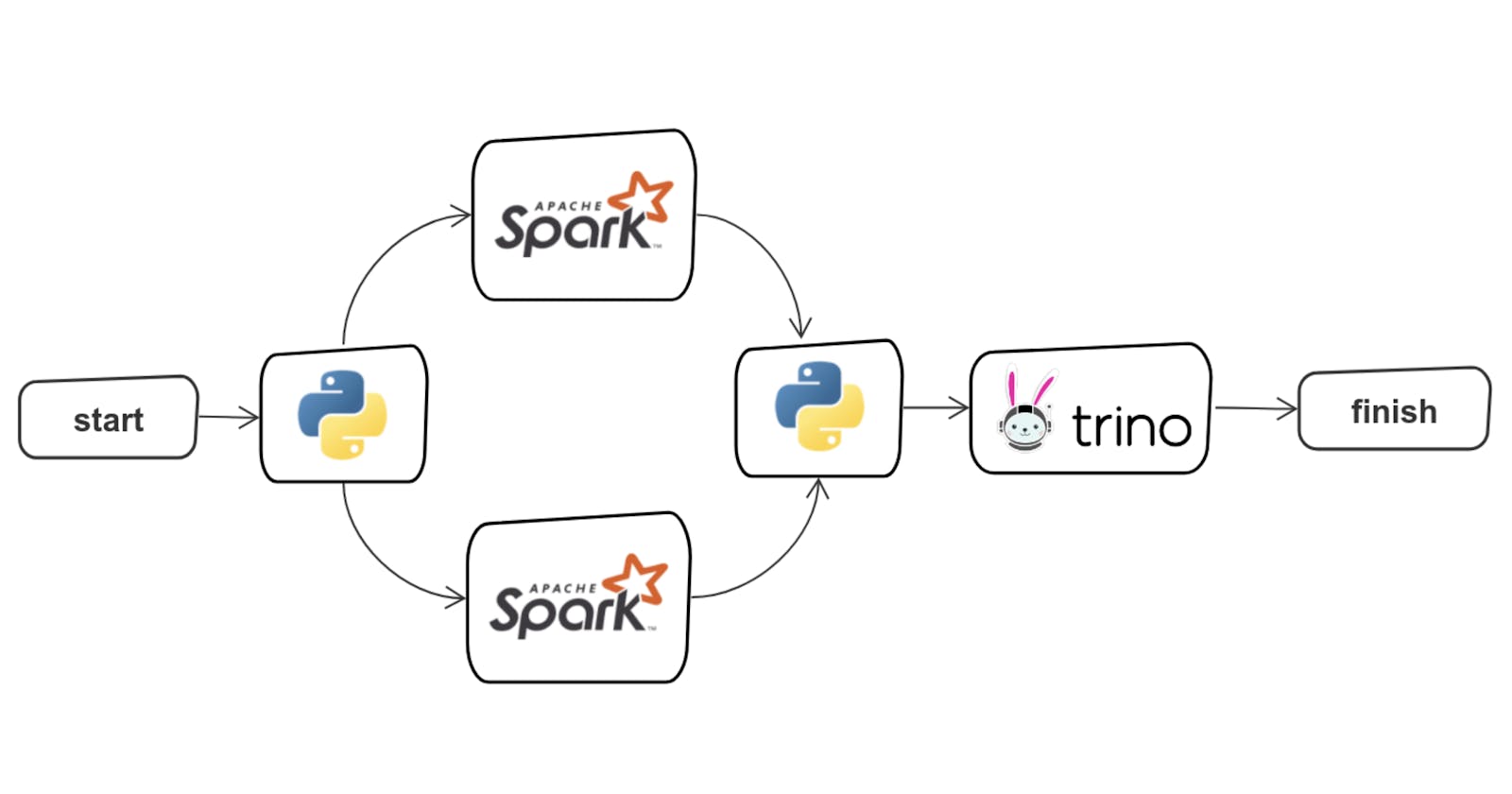
Run-time dependency is an important consideration when building machine learning or data processing pipelines. Consider a case where you want to query...