




Run-time dependency is an important consideration when building machine learning or data processing pipelines. Consider a case where you want to query your database x number of times where x can be resolved only at run-time. Here, looping is the ultimate solution (manually writing by hand is unfeasible!). When there’s a loop in the picture, a machine learning or data processing job needs to pick up an unknown variable at run-time and then build a pipeline based on the variable’s value. This process isn’t static and has to happen on the fly at run-time.
Dynamic workflows in Flyte intend to solve this problem for the users.
Introduction
Before we get an essence of how a dynamic workflow works, let’s understand the two essential components of Flyte, namely task and workflow. A task is the primary building block of any pipeline in Flyte. A collection of tasks in a specified order constitutes a workflow. A workflow in Flyte is represented using a directed acyclic graph (DAG).
A workflow can either be static or dynamic. A workflow is static when its DAG structure is known ahead of time, whereas a workflow is dynamic when the DAG structure is computed at run-time, potentially using the run-time inputs given to a task.
Inducing dynamism into data processing or machine learning workflows is a beneficial aspect in Flyte if:
- the workflow depends on the run-time variables, or
- a plan of execution (or) workflow within a task is required. This helps keep track of data lineage encapsulated in the dynamic workflow within the DAG, which isn’t the case with a task.
Note: A task is a general Python function that doesn't track the data flow within it.
Besides, a dynamic workflow can also help in building simpler pipelines. Vaguely, it provides the flexibility to mold workflows according to the project’s needs, which may not be possible with static workflows.
When to Use Dynamic Workflows?
- If a dynamic modification is required in the code logic—determining the number of training regions, programmatically stopping the training if the error surges, introducing validation steps dynamically, data-parallel and sharded training, etc.
- During feature extraction, if there’s a need to decide on the parameters dynamically.
- To build an AutoML pipeline.
- To tune the hyperparameters dynamically while the pipeline is in progress.
How Flyte Handles Dynamic Workflows
Flyte can combine the typically static nature of DAGs with the dynamic nature of workflows. With a dynamic workflow, just as a typical workflow, users can perform any arbitrary computation by consuming inputs and producing the outputs. It is capable of yielding a workflow, where the instances or the children (tasks/sub-workflows) can programmatically be constructed using inputs at execution (run) time. Hence, it is called “dynamic workflow”.
A dynamic workflow is modeled in the backend as a task, but at the execution (run) time, the function body is run to produce a workflow.
Here’s an example that “explores the classification accuracy of the KNN algorithm with k values ranging from two to seven”.
Let's first import the libraries.
"""
Explore the classification accuracy of the KNN algorithm with k values ranging from 2 to 7
Install the following libraries before running the model (locally).
* pip install scikit-learn
* pip install joblib
"""
import os
import typing
from statistics import mean, pstdev
import joblib
from flytekit import Resources, dynamic, task, workflow
from flytekit.types.file import JoblibSerializedFile
from sklearn.datasets import make_classification
from sklearn.model_selection import RepeatedStratifiedKFold, cross_val_score
from sklearn.neighbors import KNeighborsClassifier
Next, we define tasks to fetch the dataset and build models with different k values.
@task(cache=True, cache_version="0.1", limits=Resources(mem="600Mi"))
def get_dataset() -> (typing.List[typing.List[float]], typing.List[float]):
"""Fetch the dataset"""
# Generate a random n-class classification problem
X, y = make_classification(
n_samples=5000, n_features=15, n_informative=10, n_redundant=3, random_state=5
)
return X.tolist(), y.tolist()
@task(cache=True, cache_version="0.1", limits=Resources(mem="600Mi"))
def get_models() -> typing.List[JoblibSerializedFile]:
"""Get a list of models to evaluate, each with a specific 'k' value"""
models = list()
for n in range(2, 8):
fname = "model-k" + str(n) + ".joblib.dat"
# Serialize model using joblib
joblib.dump(KNeighborsClassifier(n_neighbors=n), fname)
models.append(fname)
return models
We now define a dynamic workflow that loops through the models and computes the cross-validation score. Moreover, we define a helper task that returns the appropriate score for every model.
@task
def helper_evaluate_model(name: str, scores: typing.List[float]) -> typing.List[str]:
"""A helper task to showcase calling task within a dynamic workflow loop"""
return [
str(os.path.basename(name)),
str(round(mean(scores), 2)),
str(round(pstdev(scores), 3)),
]
@dynamic(cache=True, cache_version="0.1", limits=Resources(mem="1000Mi"))
def evaluate_model(
models: typing.List[JoblibSerializedFile],
X: typing.List[typing.List[float]],
y: typing.List[float],
) -> typing.List[typing.List[str]]:
"""
A dynamic workflow to compute the cross-validation score across different models
All Promise objects passed as arguments are accessible here
This is compiled at execution time
"""
final_result = list()
"""
models = get_models()
for model_ser in models:
...
This results in a compilation error as 'models' is a Promise object which cannot be looped over
"""
# Loop through the list of models
for model_ser in models:
# Fetch the unserialized model
model = joblib.load(model_ser)
# Cross-validation splitting strategy
cv = RepeatedStratifiedKFold(n_splits=7, n_repeats=2, random_state=1)
# Peform cross-validation
scores = cross_val_score(model, X, y, scoring="accuracy", cv=cv, n_jobs=-1)
"""
'model', 'cv', and 'scores' are all accessible
Similarty, return values of python functions (non-tasks) are accessible
"""
"""
Call a task and store the file name, accuracy, and standard deviation
The return value of the task is a Promise object
"""
final_result.append(
helper_evaluate_model(name=str(model_ser), scores=scores.tolist())
)
return final_result
Finally, we define a workflow that calls the above-mentioned tasks and dynamic workflow.
@workflow
def wf() -> typing.List[typing.List[str]]:
"""
A workflow to call the concerned tasks
This is compiled at compile time
"""
"""Get the dataset. 'X' and 'y' aren't accessible as they are Promise objects"""
X, y = get_dataset()
"""Get the models to evaluate. 'models' is a Promise object"""
models = get_models()
"""
Fetch the accuracy
When 'models' is sent to a dynamic-workflow/task, it becomes accessible in the respective Flyte units
"""
return evaluate_model(models=models, X=X, y=y)
if __name__ == "__main__":
print(wf())
When the code is run locally, the following output is shown (the output is arbitrary):
[['model-k2.joblib.dat', '0.92', '0.01'], ['model-k3.joblib.dat', '0.94', '0.008'], ['model-k4.joblib.dat', '0.94', '0.006'], ['model-k5.joblib.dat', '0.95', '0.008'], ['model-k6.joblib.dat', '0.95', '0.009'], ['model-k7.joblib.dat', '0.95', '0.008']]
get_dataset, get_models, helper_evaluate_model are tasks, whereas evaluate_model is a dynamic workflow and wf is a workflow.
evaluate_model is dynamic because internally, it loops over a variable that’s known only at run-time. It also encapsulates a helper_evaluate_model task which gets called a specified number of times (depends on the number of KNN models).
If evaluate_model is given the @workflow decorator, the compilation fails ('Promise' object is not iterable) due to the inability to decide upon a static DAG.
Points to remember:
- A task runs at run-time, whereas a workflow runs at compile time. However, a dynamic workflow gets compiled at run-time and runs at run-time.
- When a task is called within a dynamic workflow (or simply, a workflow), it returns a Promise object. This object cannot be directly accessed within the Flyte entity. Nonetheless, if it needs to be accessed, pass it to a task or a dynamic workflow that unwraps its value.
- Values returned from a Python function (not a task) are accessible within a dynamic workflow (or simply, a workflow).
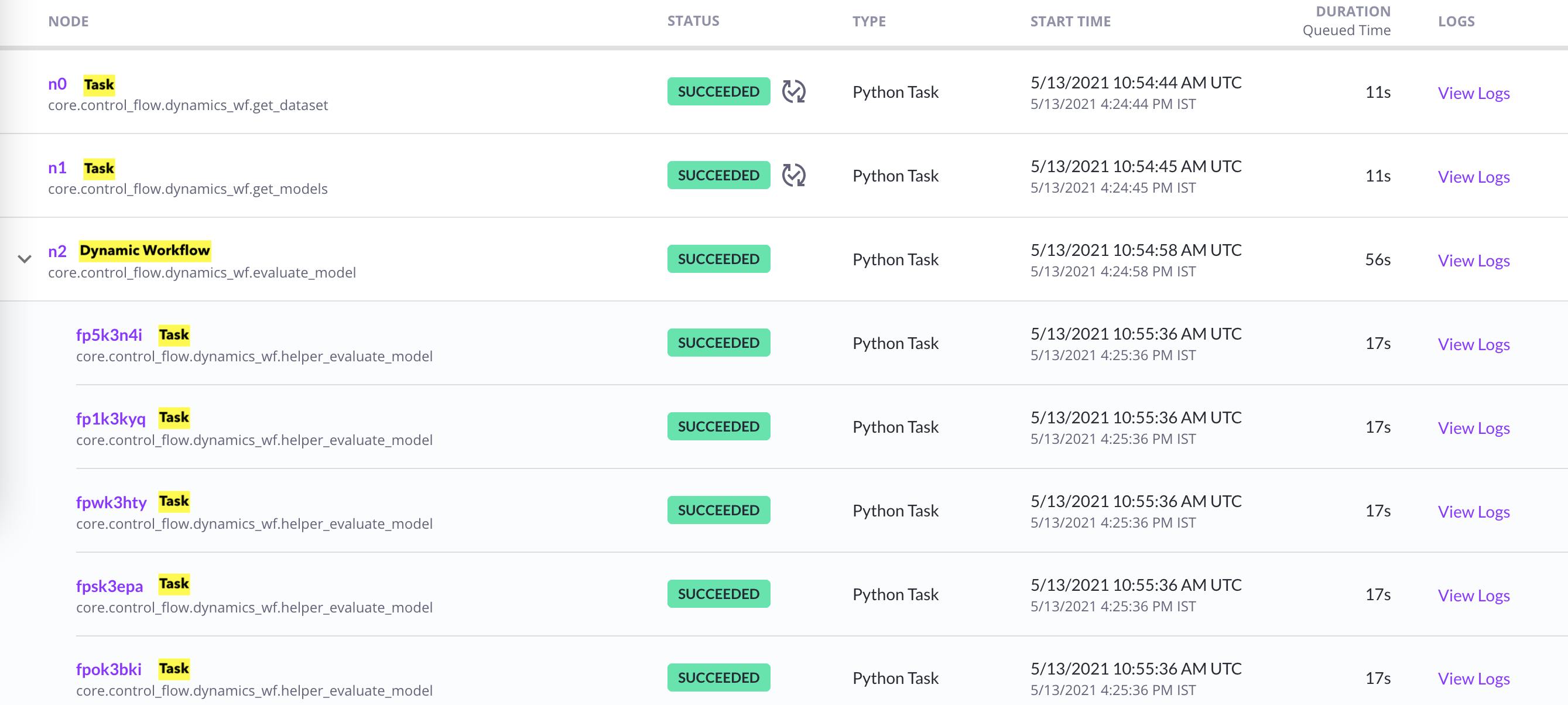 Figure: Nodes’ in the Flyte back-end
Figure: Nodes’ in the Flyte back-end
Here’s an animation depicting the data flow through Flyte's entities (task, workflow, dynamic workflow) for the above code:
To learn more about dynamic workflows, refer to the docs. There’s also a House Price Prediction example that you could refer to.
Conclusion
A Dynamic Workflow is a hybrid of a task and a workflow. It is useful when you have to decide on the parameters at run time dynamically.
A dynamic workflow, when combined with a map task, becomes an all-powerful combination. Dynamic workflow helps in spawning new instances (tasks/sub-workflows) within a workflow, and a map task spawns multiple inputs in a single task which leads to the creation of dynamically parallel pipelines. All of this can be implemented easily within Flyte.
We will talk about the map task in a follow-up post—stay tuned! ⭐️
Reference: machinelearningmastery.com/dynamic-ensemble..
Cover Image Credits: Photo by Julian Hochgesang on Unsplash.