




This blog is with reference to a talk titled “Efficient Data Parallel Distributed Training with Flyte, Spark & Horovod”, presented by Katrina Rogan and Ketan Umare at OSPOCon 2021, Seattle.
To get the ball rolling, let’s understand what the title implies.

- Distributed Training: Distributed training is the process of distributing the machine learning workload to multiple worker processes. It is helpful in scenarios where we have time- and compute-intensive deep learning workloads to run.
- Data-Parallel: Distributed training can be two types: model-parallel and data-parallel. Model-parallel training parallelizes the model where the global parameters are usually shared amongst the workers. Data-parallel training parallelizes the data, requiring sharing weights after one batch of training data. Our focus in this blog would be on data-parallel distributed training.
- Horovod: Horovod is a distributed deep learning training framework for TensorFlow, Keras, PyTorch, and Apache MXNet. The goal of Horovod is to make distributed deep learning fast and easy to use. It uses the all-reduce algorithm for fast distributed training rather than a parameter server approach (all-reduce vs. parameter server). It builds on top of low-level frameworks like MPI and NCCL and provides optimized algorithms for sharing data between parallel training processes.
- Flyte: Flyte is a workflow orchestration engine that seamlessly builds machine learning and data pipelines.
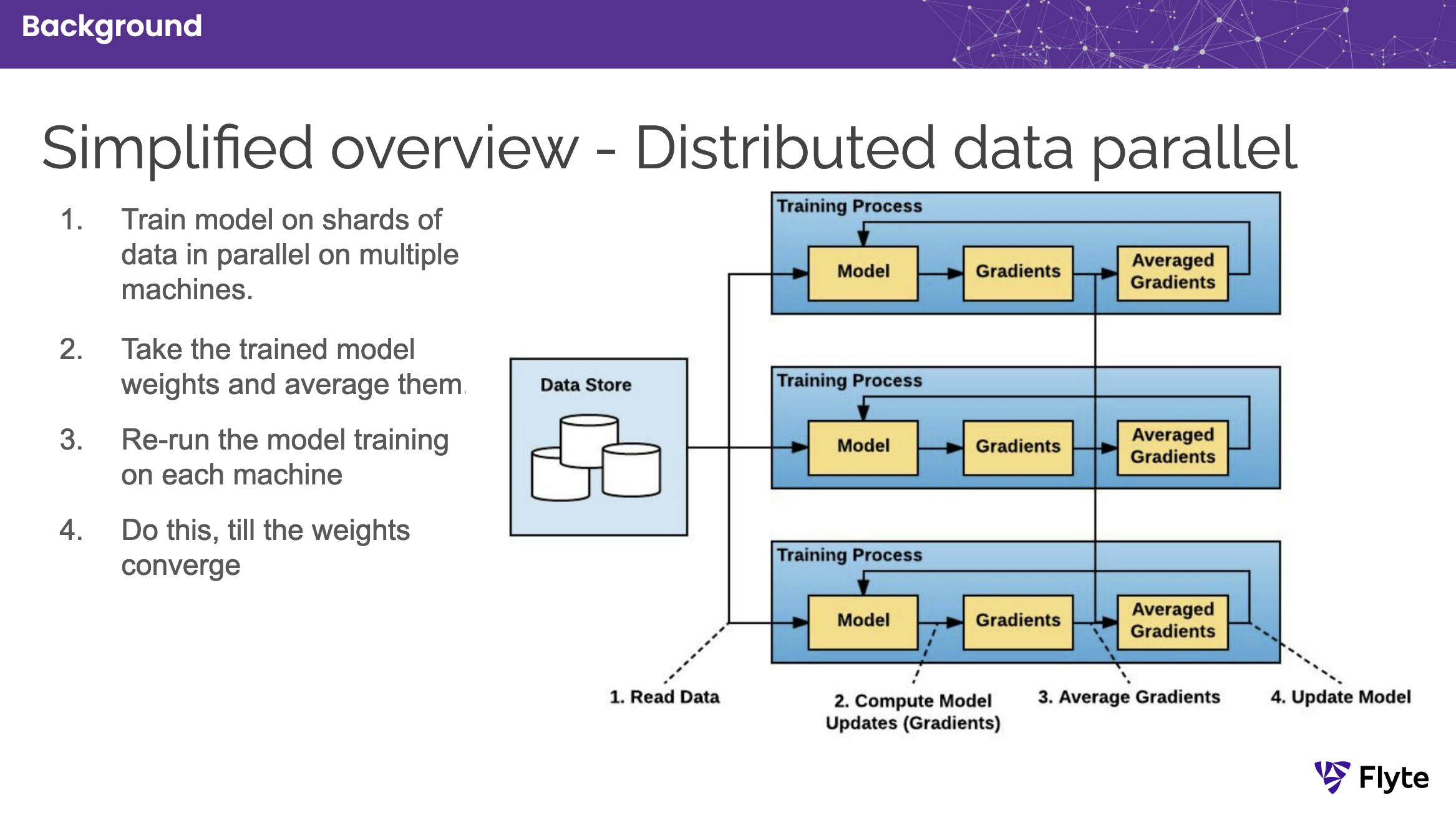 Figure 1. Data-parallel distributed training
Figure 1. Data-parallel distributed training
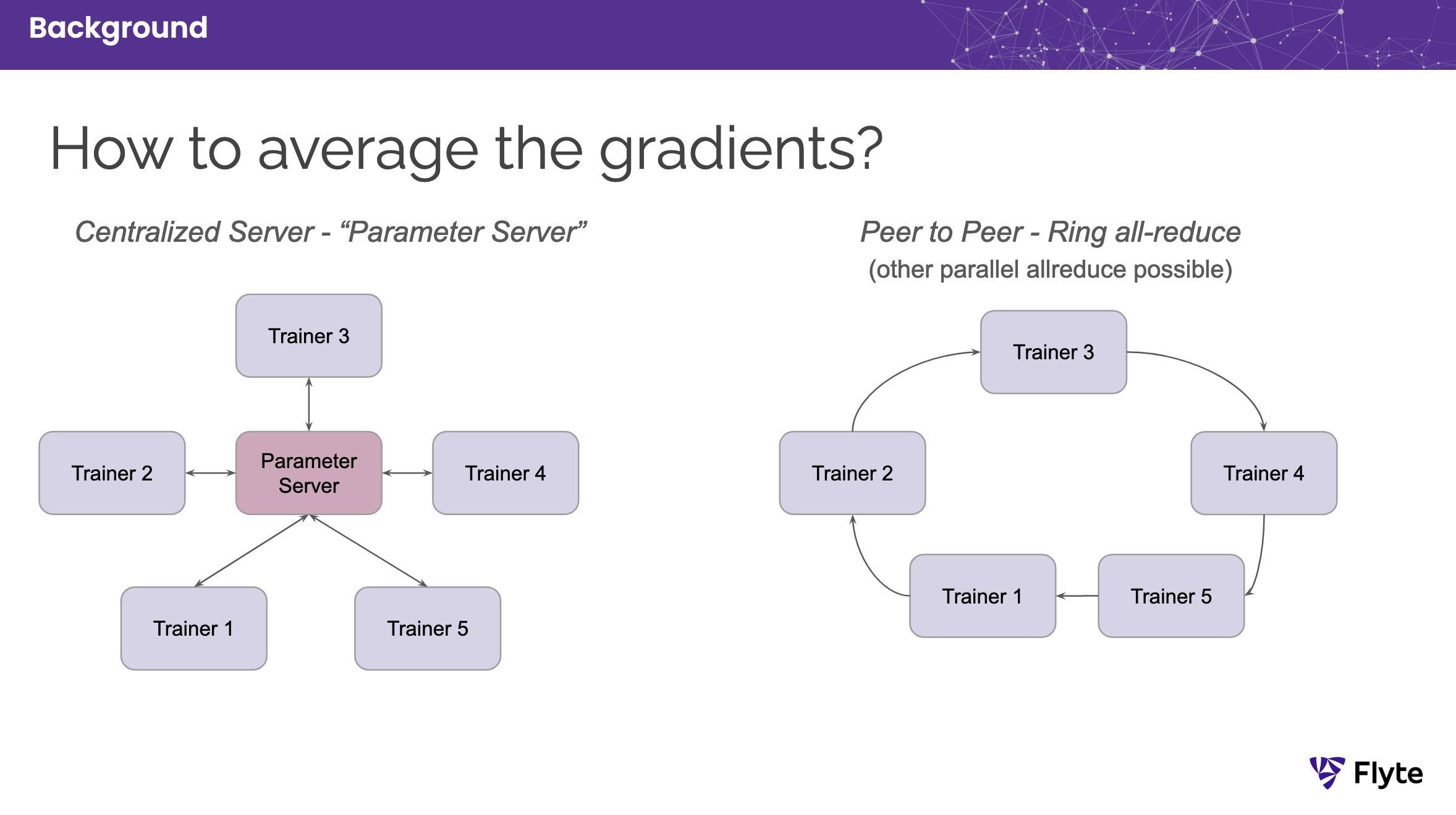 Figure 2. Parameter server vs. ring all-reduce
Figure 2. Parameter server vs. ring all-reduce
With Horovod and Flyte, we can build robust distributed data pipelines. The two possible use cases that we shall explore in this blog integrate with:
- Spark
- MPI Operator
Spark
Spark is a data processing and analytics engine to deal with large-scale data. Here’s how Horovod-Spark-Flyte can be beneficial: Horovod provides the distributed framework, Spark enables extracting, preprocessing, and partitioning data, Flyte can stitch the former two pieces together, e.g., by connecting the data output of a Spark transform to a training system using Horovod while ensuring high utilization of GPUs!
In the next section, let’s understand how the integration took shape.
Here’s an interesting fact about Spark integration:
Spark integrates with both Horovod and Flyte
Horovod and Spark
Horovod implicitly supports Spark. It facilitates running distributed jobs in Spark clusters. In situations where training data originates from Spark, Horovod on Spark enables a tight model design loop in which data processing, model training, and model evaluation are all done in Spark[1].
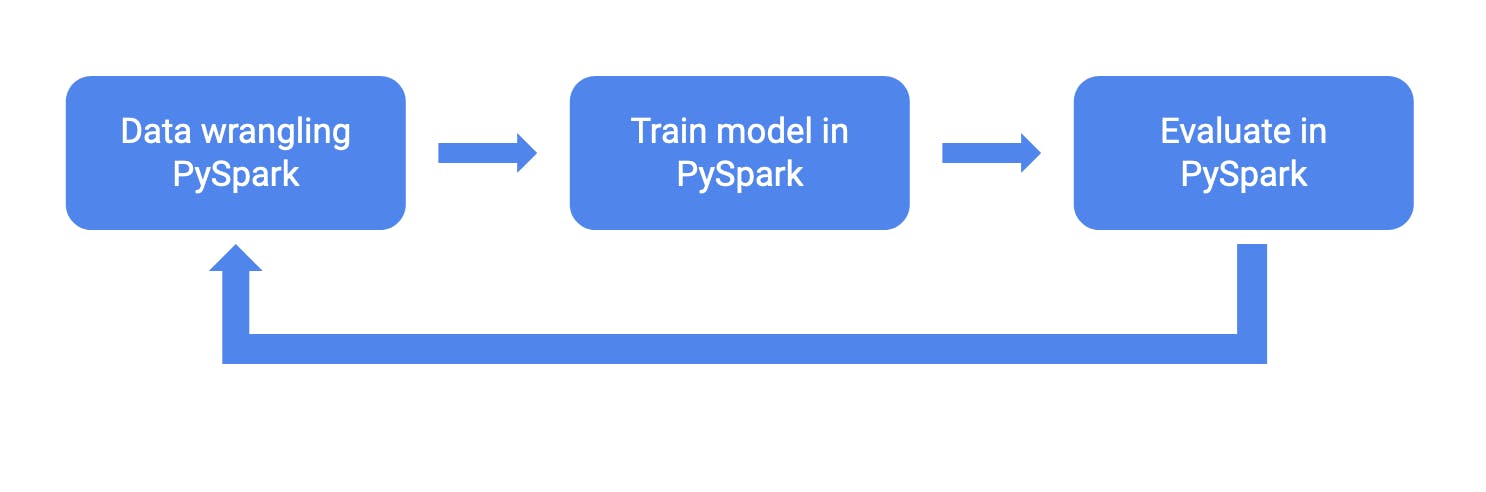
Figure 3. Pre-process, train, and evaluate in the same environment (ref: Horovod Adds Support for PySpark and Apache MXNet and Additional Features for Faster Training )
In our example, to activate Horovod on Spark, we use an Estimator API. An estimator API abstracts the data processing, model training and checkpointing, and distributed training, making it easy to integrate and run our example code. There is also a low-level Run API available, which offers a more fine-grained control.
Since we use the Keras deep learning library, here’s how we install the relevant Horovod packages:
HOROVOD_WITH_MPI=1 HOROVOD_WITH_TENSORFLOW=1 pip install --no-cache-dir horovod[spark,tensorflow]==0.22.1
The installation includes enabling MPI and TensorFlow environments.
Flyte and Spark
Flyte can execute Spark jobs natively on a Kubernetes Cluster, which manages a virtual cluster’s lifecycle, spin-up, and tear down. It leverages the open-sourced Spark On K8s Operator and can be enabled without signing up for any service. This is like running a transient spark cluster—a type of cluster spun up for a specific Spark job and torn down after completion.
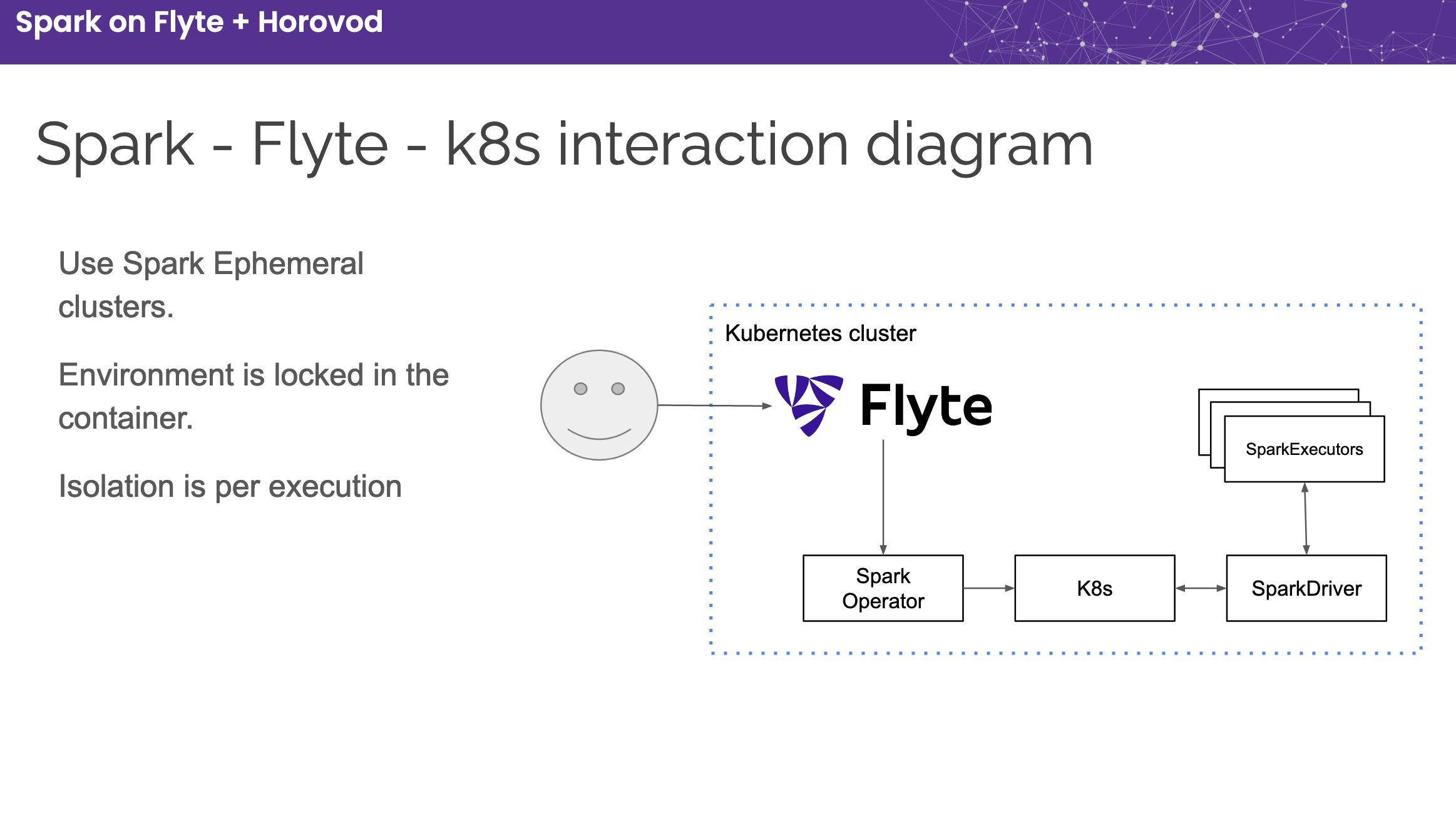 Figure 4. Flyte-Spark integration
Figure 4. Flyte-Spark integration
To install the Spark plugin on Flyte, we use the following command:
pip install flytekitplugins-spark
Summing-up: Horovod, Spark, and Flyte
The problem statement we are looking at is forecasting sales using Rossmann store sales data. Our example is an adaptation of the Horovod-Spark example. Here’s how the code is streamlined:
In a Spark cluster that is set up using the Flyte-Spark plugin:
- Fetch the Rossmann sales data
- Perform complicated data pre-processing on Spark DataFrame
- Define a Keras model and perform distributed training using Horovod on Spark
- Generate predictions and store them in a submission file
Flyte-Spark Plugin
Flyte-Spark plugin can be activated by applying Spark cluster configuration to a Flyte task.
@task(
task_config=Spark(
# this configuration is applied to the spark cluster
spark_conf={
"spark.driver.memory": "2000M",
"spark.executor.memory": "2000M",
"spark.executor.cores": "1",
"spark.executor.instances": "2",
"spark.driver.cores": "1",
"spark.sql.shuffle.partitions": "16",
"spark.worker.timeout": "120",
}
),
cache=True,
cache_version="0.2",
requests=Resources(mem="1Gi"),
limits=Resources(mem="1Gi"),
)
def horovod_spark_task(
data_dir: FlyteDirectory, hp: Hyperparameters, work_dir: FlyteDirectory
) -> FlyteDirectory:
...
On applying Spark config to horovod_spark_task, the task behaves like a PySpark task. All attributes in the spark_conf correspond to the pre-existing Spark attributes.
Keep in mind that the horovod_spark_task encapsulates data pre-processing, training, and evaluation.
@task(...)
def horovod_spark_task(
data_dir: FlyteDirectory, hp: Hyperparameters, work_dir: FlyteDirectory
) -> FlyteDirectory:
max_sales, vocab, train_df, test_df = data_preparation(data_dir, hp)
# working directory will have the model and predictions as separate files
working_dir = flytekit.current_context().working_directory
keras_model = train(
max_sales,
vocab,
hp,
work_dir,
train_df,
working_dir,
)
return test(keras_model, working_dir, test_df, hp)
Note: You can have two separate Spark tasks for data processing and training in Flyte. Training can also be done through Flyte’s MPIOperator, which shall be seen in the MPIOperator section.
In the train function, we define our Keras model and perform distributed training on Spark data using Horovod’s Estimator API.
Horovod Estimator API
The Keras estimator in Horovod can be used to train a model on an existing Spark DataFrame, leveraging Horovod’s ability to scale across multiple workers without any specialized code for distributed training.
import horovod.spark.keras as hvd
from horovod.spark.common.backend import SparkBackend
from horovod.spark.common.store import Store
def train(
max_sales: float,
vocab: Dict[str, List[Any]],
hp: Hyperparameters,
work_dir: FlyteDirectory,
train_df: pyspark.sql.DataFrame,
working_dir: FlyteDirectory,
):
...
# Horovod: run training
store = Store.create(work_dir.remote_source)
backend = SparkBackend(
num_proc=hp.num_proc,
stdout=sys.stdout,
stderr=sys.stderr,
prefix_output_with_timestamp=True,
)
keras_estimator = hvd.KerasEstimator(
backend=backend,
store=store,
model=model,
optimizer=opt,
loss="mae",
metrics=[exp_rmspe],
custom_objects=CUSTOM_OBJECTS,
feature_cols=all_cols,
label_cols=["Sales"],
validation="Validation",
batch_size=hp.batch_size,
epochs=hp.epochs,
verbose=2,
checkpoint_callback=ckpt_callback,
)
keras_model = keras_estimator.fit(train_df).setOutputCols(["Sales_output"])
...
return keras_model
After training, the Estimator returns a Transformer representation of the trained model. The model transformer can be used like any Spark ML transformer to make predictions on an input DataFrame, writing them as new columns in the output DataFrame[1].
pred_df = keras_model.transform(test_df)
The end-to-end code is available in the Flyte documentation in the Forecast Sales Using Rossmann Store Sales Data With Horovod and Spark section.
Pitfalls of Using Horovod on Spark
- Lack of Spark expertise in your organization: data-scientists do not already use Spark
- A hard boundary between data processing on the RDD and training on a Parquet file, which introduces overhead and operational complexity (where will the Parquet file live, how long will we persist it, etc.).
- Lack of visibility: Horovod processes run within Spark executors. However, Horovod processes do not run as tasks within the Spark task graph because of which failures may be hard to track.
- Your data-processing is on unstructured data, and simple map operations work better
MPI Operator has also been developed as part of an effort to integrate Horovod.
MPI Operator
The MPI operator plugin within Flyte uses the Kubeflow MPI Operator, which makes it easy to run an all reduce-style distributed training on Kubernetes. It provides an extremely simplified interface for executing distributed training using MPI.
MPI and Horovod together can be leveraged to simplify the process of distributed training. The MPI Operator provides a convenient wrapper to run the Horovod scripts[2].
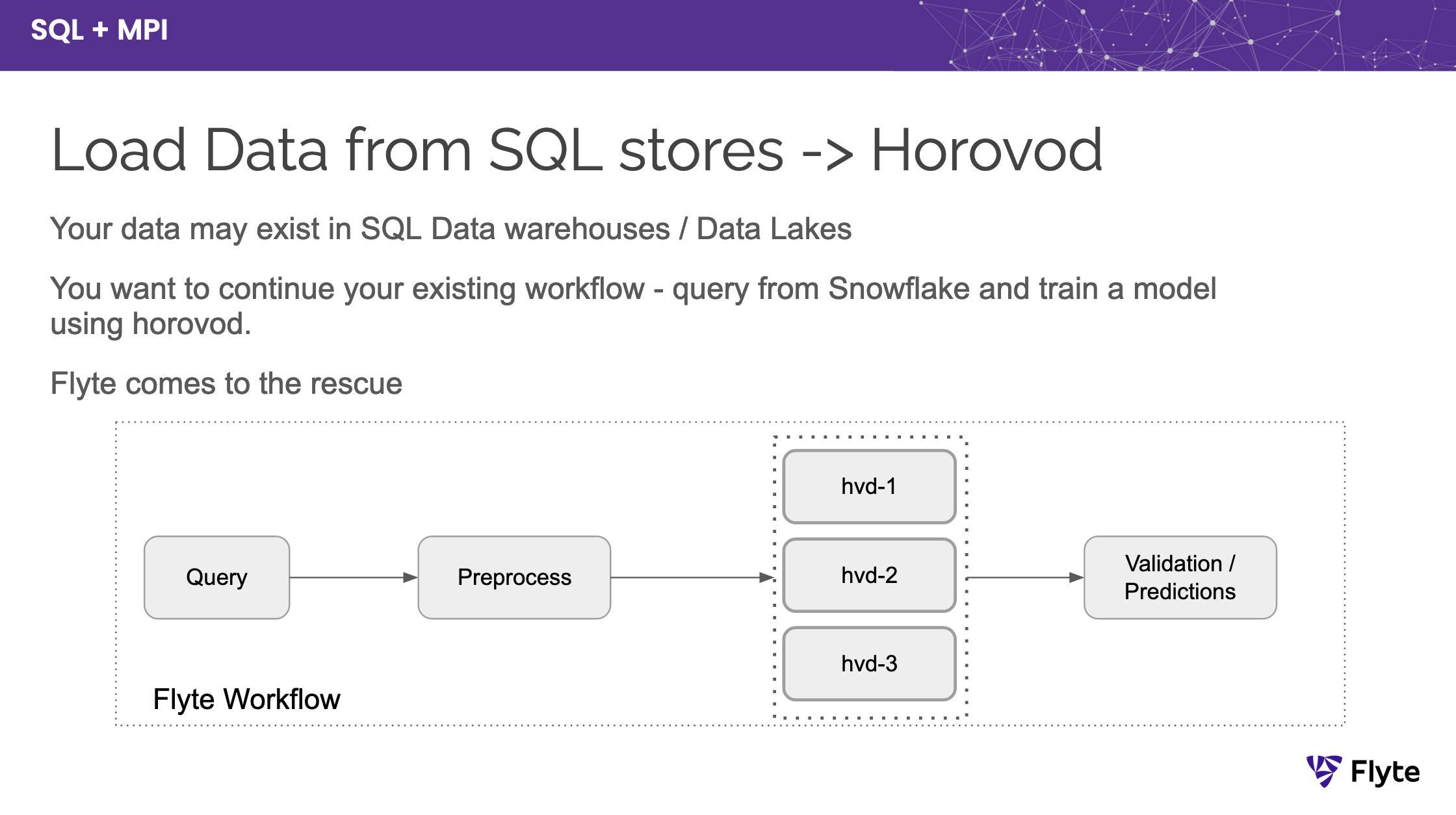 Figure 5. Use Flyte’s MPIOperator to perform distributed training through Horovod
Figure 5. Use Flyte’s MPIOperator to perform distributed training through Horovod
To use the Flytekit MPI Operator plugin, we run the following command:
pip install flytekitplugins-kfmpi
Here’s an example of an MPI-enabled Flyte task:
@task(
task_config=MPIJob(
# number of workers to be spawned in the cluster for this job
num_workers=2,
# number of launcher replicas to be spawned in the cluster for this job
# the launcher pod invokes mpirun and communicates with worker pods through MPI
num_launcher_replicas=1,
# number of slots per worker used in the hostfile
# the available slots (GPUs) in each pod
slots=1,
),
requests=Resources(cpu='1', mem="3000Mi"),
limits=Resources(cpu='2', mem="6000Mi"),
retries=3,
cache=True,
cache_version="0.5",
)
def mpi_task(...):
# do some work
pass
An end-to-end MPIJob example with Horovod can be found in the Flyte documentation.
Horovod, Spark/MPI Operator, and Flyte together could help run distributed deep learning workflows much faster! If you happen to utilize either of the two integrations, do let us know what you think of it.
Future work: use Streaming TypeTransformers to improve GPU Utilization.
At scale, one of the challenges of training is the utilization of GPUs. In the case of downloading data, utilization of GPUs drops as the data is downloaded first.
Streaming TypeTransformers can help stream data as it is prepared into the training phase without sitting idle waiting for all the data to be processed. The Flyte community is working on allowing data to be streamed to training instances to improve the utilization of the GPUs.