




By: Jake Neyer (Software Engineer at Striveworks)
At Striveworks, we are building a one-of-a-kind data science platform by integrating the building blocks that most data science teams already have in their tool belts and adding a few new ones to streamline the process to get from a business question to a production solution.
 Figure 1: Chariot Platform
Figure 1: Chariot Platform
Chariot is built to consolidate many standard parts of the data science lifecycle. Annotating, experimenting, training, ELT/ETL, data warehousing, and knowledge persistence, to name a few. At the core of the system is a powerful workflow engine for managing pipelines and analytics at scale (both small and large). So what is a workflow engine?
Workflow Engines
Workflow engines manage logical processes within a system. A process could be a simple business rule or an inference call to a machine learning model. Typically, the process flows are represented as directed acyclic graphs (DAGs), where each node in a graph is a process or a set of processes. The flows are an abstracted, logical representation of the work that needs to be done.
In our opinion, the workflow engine is a necessary component for any MLOps platform—why you may ask?
There is no longer a need for ad-hoc combinations of scripts that run in crontabs. The workflow engine enables versioned, modular, and shareable ways to enable ETL/ELT. It’s very much like the GitOps of data. The workflow engine also lends visibility into how all data within the system is being created and mutated. This kind of insight into your data and data flow is critical to the ML use case. Decisions need to be based on evidence with a complete chain of custody that allows decision-makers to see how they got from question to answer.
Our Choice
There have been dozens of workflow engines that have popped up in recent years. Each workflow engine implementation has its own benefits and disadvantages. We had the opportunity and responsibility to choose a solution most appropriate to our use case of AI-enabled operational data science. In our estimate, the most critical features we were looking for were data provenance, reproducibility, multi-tenant architecture, and scale.
We originally started building our own workflow engine—adding to the dozens that were already out there. As we developed our own, we saw that our architecture and design decisions were converging with those that Flyte already had in place. Seeing that happen, we began to adopt and integrate Flyte into our system.
Flyte checked the boxes.
Provenance
In terms of data provenance, Flyte can capture strongly typed artifacts from tasks with its Data Catalog. The Data Catalog can be used for performance benefits such as memoization and can be used to create data lineage for stored artifacts. What this means is each artifact can be associated with versioned task execution. Below is an example of what that schema looks like.
Dataset {
project: Flyte project the task was registered in
domain: Flyte domain for the task execution
name: flyte_task-<taskName>
version: <cache_version>-<hash(input params)>-<hash(output params)>
}
Artifact {
id: uuid
Metadata: [executionName, executionVersion]
ArtifactData: [List of ArtifactData]
}
ArtifactData {
Name: <output-name>
value: <offloaded storage location of the literal>
}
While Flyte offers a handy basic set of provenance information, we wanted system-wide provenance information, including the workflow engine and various other components: model training services, annotation services, APIs, and data stores. Luckily, Flyte does offer a fantastic API/event stream for gathering the information we need. We ended up creating a proxy within Chariot to record the lineage information from Flyte and our other microservices. This proxy is fed context from the system reading the Flyte workflow event stream. Upon receiving a request, this proxy will route it to its appropriate destination and use configurable lineage gatherers to gather provenance information from the request.
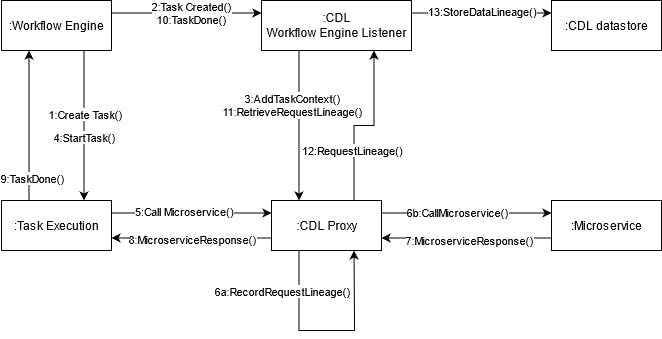 Figure 2: Chariot Data Lineage
Figure 2: Chariot Data Lineage
Reproducibility
Flyte objects are immutable, meaning each task and workflow are versioned rather than mutated. This means reproducing a set of tasks or a workflow is as simple as inheriting the desired version number and re-executing. Barring any weird non-deterministic behavior from the logic within a task (e.g., random number generation), tasks will return the same output with the same set of inputs every time. At Striveworks, we believe that ETL should almost always have deterministic behavior. That way, the all-important chain of custody for data used to answer business or operational questions is preserved. Flyte makes treating ELT/ETL operations deterministically extremely easy. The Flyte team wrote an excellent post about reproducibility titled “Why Is the Maintainability and Reproducibility of Machine Learning Models Hard?” that I recommend checking out.
Multi-Tenant
Multi-tenant architecture is becoming more and more critical. ETL/ELT within an organization typically happens across multiple teams. Separating problem domains and areas of concern becomes an import utility. With Flyte, this is accomplished in two ways: Projects and Domains.
Projects allow grouping workflows and tasks that fall within the same problem domain, which will enable teams or individuals to control a particular namespace without it being polluted by workflows and tasks from other individuals or teams in the organization.
Domains represent a further separation of workflows and tasks by isolation of resources and configuration. This can be useful for experimenting and running production pipelines entirely separately. Experimental and development workflows can be allocated fewer physical resources to conserve costs; production workflows can be allocated more to meet business needs. Domains can also be used to separate security domains. Imagine a scenario where one set of hardware needs to be PCI DSS/HIPAA compliant, but another needs to conform to a different compliance structure. Domains can ensure that the workflows processing specific data remain isolated from hardware running other ETL/ELT processes.
These two layers of abstraction allow for multiple teams to work effectively, jointly, and independently. As a final additional benefit, they also allow software and infrastructure to be loosely coupled with one another.
Scale
As a system grows and entropy is introduced, a critical component such as the workflow engine mustn’t break down. Flyte’s control loop architecture allows for massive scale and performance. Its bottleneck typically becomes external API calls such as those from the KubeAPI or the plugins it supports, such as SageMaker. Flyte natively uses Kubernetes but is not limited to a single control plane. This means that it can be spread across various Kubernetes control planes to support larger-scale implementations. Within our particular environment, we have not met any challenges using Flyte concerning scale at this point. Lyft has also used Flyte to run 40+ million container executions per month!
While people often think of “scale” as large scale, we also wanted to focus on a smaller scale for things like edge deployments. Flyte’s application overhead is small enough to run on a small microk8s or k3s cluster, which means that we can maintain a consistent set of applications for enterprise and edge use-cases. Flyte is lightweight and portable, making installation and usage consistent and flexible. Also, it’s written in Go ❤️!
Not A Panacea
Out of the box, Flyte solved many of the things we wanted to accomplish with our workflow engine, but not quite everything.
We wanted to accomplish one significant thing with our workflow engine: the ability to efficiently horizontally scale our models for inference independently from our workflows. We also wanted multiple workflows to be able to share the same inference models without duplicating the compute resources required to do so. Specifically, we wanted to use fractional GPUs for multiple workflows rather than have a 1:1 relationship with containers and GPUs. This is something that we did not see a native solution for within Flyte. For this, we created a Knative serving framework named ICOW (Inference with Collected ONNX Weights). ICOW allows warm GPU resources to be used for inference across multiple workflows. It also helps to minimize time to provision GPU nodes within our Kubernetes environment. If you are interested in checking it out, there’s an open-sourced version of this software for anyone to use.
We found another pain point when scoping workflow engines: you could pick one data acquisition scheme: batching or streaming. Flyte was the same way. Currently, it only supports batch processing. For many ML use-cases, both streaming and batch processing are necessary. We currently only support batch processing but are working on abstracting workflow declarations to use multiple backends: Flyte for batch process and something else for streaming.
Still a Win
 Figure 3: Chariot using Flyte
Figure 3: Chariot using Flyte
No workflow engine is going to be absolutely perfect for all of the use cases in an organization. However, Flyte offers almost all the things we wanted, plus a few extra bells and whistles. The Flyte team is constantly improving the product, and we at Striveworks are enthusiastic about using and contributing to the platform with them!
This is just a tiny peek into how we at Striveworks are handling workflows with our Chariot platform. If you’d like to learn about Chariot or how we are using Flyte, please stop by our Slack!