




Whether it is asking, “Why do 87% of data science projects never make it into production?” or trying to make sense of a “hot mess” called MLOps, debates around machine learning in production have never really subsided. Machine Learning research is booming, yet the best way to run models in production is still a hot topic. With the arrival of a variety of MLOps tools, the push from development to production of ML models is turning out to be harder than anticipated due to the complexity of rebundling the tools onto a single platform.
To ease this process precisely in the distributed training area, we’ve come up with a Ray + Flyte integration that adds support for native distributed computing on Flyte.
Ray is an open-source framework that provides a simple, universal API for building distributed applications. Integrating Ray tasks into Flyte opens up all the possibilities machine learning engineers have come to rely on with Ray.
KubeRay is a Kubernetes operator that handles Ray cluster life cycles. It has tools to improve the Ray experience on Kubernetes.
Flyte is an open-source data, ML, and infrastructure orchestrator that makes it easy to create, scale and maintain concurrent workflows.
Motivation
Spotify has been a long-term customer of Flyte. A couple of months ago, we learned that ML researchers and data scientists at Spotify use an internal CLI to interact with the managed Ray infrastructure for their ad hoc ML development and experimentation, and when they promote their models from training to production, they orchestrate the workflows end-to-end, which requires manual effort.
Data scientists would rather focus on the business logic than manage infrastructure (Ray cluster in our case) or compute. It is convenient if the migration of code from local development to production happens seamlessly.
In most cases, multiple teams within an organization have the same problem, but they keep reinventing the wheel. They are in need of a collaborative and reliable ML infrastructure that can reproduce the same task without any change in setup.
Ray solidifies its place in the AI/ML framework stack. It offers performant model training at scale, alongside stability and extensibility. Integrating Flyte with Ray would serve both communities, offering easy management and performance in AI/ML operations.
Flyte and Ray
Flyte makes the tasks shareable and isolatable. The task’s dependencies are packaged in Docker images. Each task will run in a pod in Kubernetes, ensuring that it works uniformly despite differences, for instance, between development and staging. Moreover, each task is versioned and immutable on the Flyte side, which makes it easy to iterate and roll back the workflows.
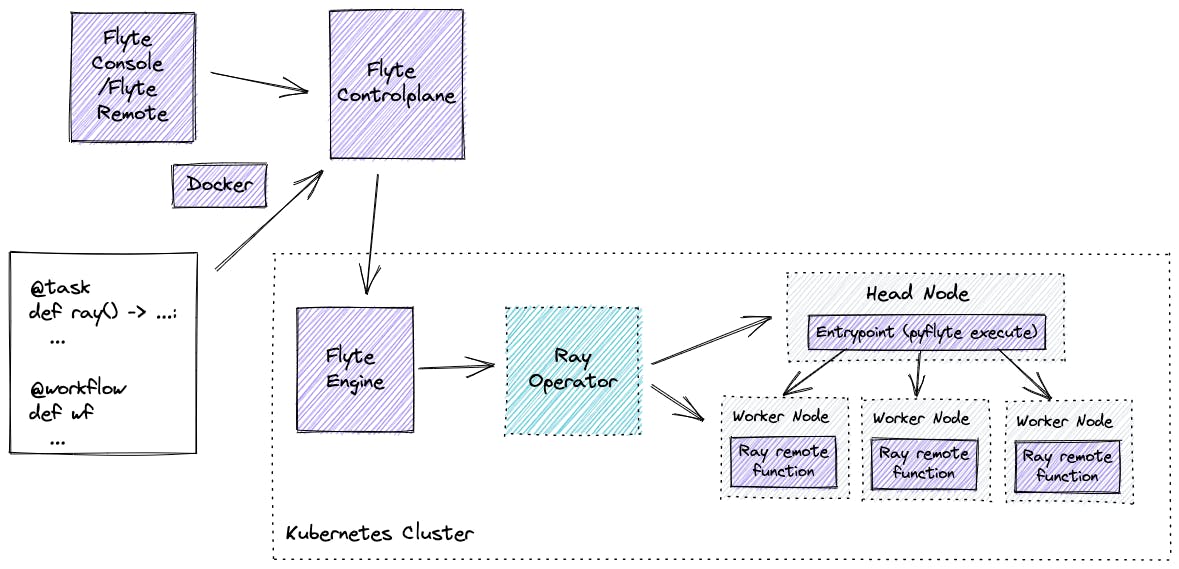
To manage the Ray cluster, Flyte leverages the open-source Ray Operator that can be enabled without signing up for any service. This operator helps launch a new Ray cluster before running the task. This is like running a transient Ray cluster — a type of cluster spun up for a specific Ray job and torn down after completion.
Flyte-Ray Plugin
With Ray native support in Flyte, users can easily transition from prototyping to production and rely on Flyte to automatically manage the Ray cluster lifecycle.- Keshi Dai (Spotify)
Installation
The Flyte-Ray plugin needs some backend setup in place.
- Install Ray operator
export KUBERAY_VERSION=v0.3.0
kubectl create -k "github.com/ray-project/kuberay/manifests/cluster-scope-resources?ref=${KUBERAY_VERSION}&timeout=90s"
kubectl apply -k "github.com/ray-project/kuberay/manifests/base?ref=${KUBERAY_VERSION}&timeout=90s"
- Enable Ray plugin in Flyte
$ kubectl edit cm flyte-propeller-config
tasks:
task-plugins:
enabled-plugins:
- container
- sidecar
- k8s-array
- ray
default-for-task-types:
container: container
sidecar: sidecar
container_array: k8s-array
ray: ray
Also, install the Flytekit Ray plugin.
pip install flytekitplugins-ray
Launch a Ray Cluster
To launch a Ray cluster, specify worker_node_config in the RayJobConfig.
Flyte-Ray plugin is activated when you apply the Ray job configuration to a Flyte task.
import typing
import ray
from flytekit import task
from flytekitplugins.ray import HeadNodeConfig, RayJobConfig, WorkerNodeConfig
@ray.remote
def f(x):
return x * x
@task(
task_config=RayJobConfig(
head_node_config=HeadNodeConfig(ray_start_params={"block": "true"}),
worker_node_config=[
WorkerNodeConfig(
group_name="ray-group", replicas=5, min_replicas=2, max_replicas=10
)
],
runtime_env={"pip": ["numpy", "pandas"]},
)
)
def ray_task(n: int) -> typing.List[int]:
futures = [f.remote(i) for i in range(n)]
return ray.get(futures)
When running remotely, Flyte creates a new Ray cluster in Kubernetes before running the Ray job. When running locally, Flyte creates a standalone Ray cluster locally for local development.
Once the cluster is ready, the Ray operator uses the Ray job submission API to submit applications to the remote Ray cluster.
The Ray operator submits the task
ray_task()to the head node by calling the HTTP endpoint of the job server.The Ray operator installs the Python dependencies passed in
RayJobConfigon both the head and worker nodes.The Ray remote function
f(x)is scheduled and executed on worker nodes, and the head node aggregates the results after the executions are finished.
Connect to an Existing Ray Cluster
To connect to an existing Ray cluster, specify the Ray cluster URL in the ray.init:
@task()
def ray_task() -> list[int]:
ray.init(address="<Ray cluster URL>")
...
Flyte submits the Ray job to the given Ray cluster both locally and remotely.
Observability
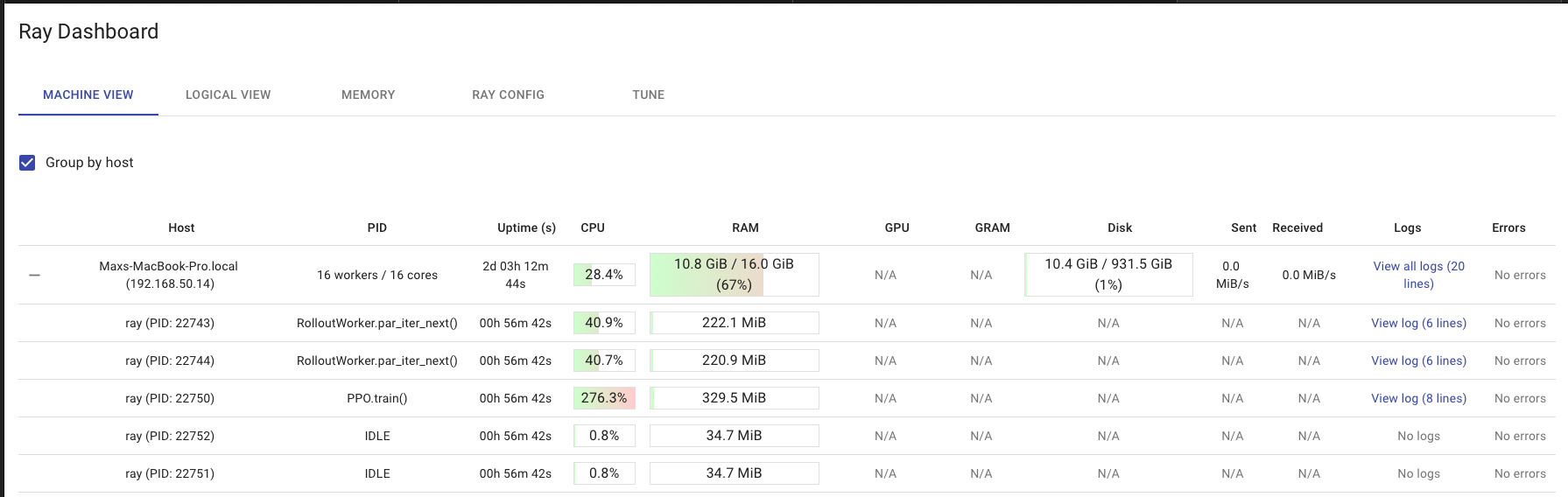
Flyte starts a Ray dashboard by default that provides cluster metrics and logs across many machines in a single pane as well as Ray memory utilization while debugging memory errors. The dashboard helps Ray users understand Ray clusters and libraries.
Conclusion
With the Flyte-Ray plugin, users can seamlessly spin up Ray clusters on Kubernetes on-demand, wherein Flyte abstracts away the Kubernetes infrastructure from users and provides a uniform way to access machine learning and data services on Kubernetes. Moreover, Flyte provides multi-tenancy/isolation between users and allows them to connect Ray with other computing platforms and services.
Future work
Flyte currently manages clusters on a per-task basis rather than reusing clusters between tasks and workflows. This does not fit well with the Ray model mitigating many of the inherent advantages. To take full advantage of Ray's benefits, multiple tasks are required to execute on the same cluster to facilitate efficient data placement and retrieval, and job scheduling. Not just Ray, but this functionality can be easily extended to support a variety of cluster types, which has the potential to become a very powerful paradigm in Flyte!