



Apache Airflow is an open-source platform that can be used to author, monitor, and schedule data pipelines. It is used by companies like Airbnb, Lyft, and Twitter, and has been the go-to tool in the data engineering ecosystem.
With an increased necessity for orchestration of data pipelines, Airflow witnessed tremendous growth. It has broadened its scope from data to machine learning and is now being used for a variety of use cases.
But since machine learning in itself demands a distinctive orchestration, Airflow needs to be extended to accommodate all the MLOps requirements.
To understand this better, let’s dive deeper into the differences between machine learning and ETL (extract-transform-load) tasks and the machine learning engineering requirements.
Machine Learning vs. ETL Tasks
Machine learning tasks have different requirements from ETL tasks.
- Machine learning needs to run resource-intensive computations.
- Machine learning needs data lineage in place or a data-aware platform to simplify the debugging process.
- Machine learning needs code to be versioned to ensure reproducibility.
- Machine learning needs infrastructure automation.
Moreover, there has been a substantial shift from static to dynamic workflows, the processes are fast and unpredictable, more computing capacity is being utilized to run workflows, and iteration is a primitive requirement, among others; hence, the legacy way of handling pipelines wouldn’t work.
Why Extend Airflow?
Airflow was designed to orchestrate data workflows. It is useful to run ETL/ELT tasks due to the ease with which it connects to a standard set of third-party sources to achieve data orchestration. Machine Learning practitioners, however, have additional requirements.
- Resource-intensive tasks: Airflow doesn’t propose a direct way to handle this, although, you can use a KubernetesPodOperator to overcome resource constraints by containerizing the code.
- Data lineage: Airflow is not a data-aware platform; it simply constructs the flow but is oblivious to the inner details comprising passing around the data.
- Versioning: There have been some indirect techniques to handle versioning of the code in Airflow, but it still isn’t an evident feature. Moreover, Airflow also doesn’t support revisiting the DAGs and re-running the workflows on demand.
- Infrastructure automation: For the most part, machine learning code needs high processing power. However, we do not want to keep the resources idle when the workflows aren’t running or when a certain number of tasks in a workflow do not require more computing capacity — this is difficult to achieve through Airflow.
- Caching: Caching task outputs can help expedite the executions and eliminate the reuse of resources, which again, Airflow doesn’t support.
Airflow supports building machine learning pipelines by leveraging operators such as Amazon Sagemaker and Databricks. The issue is that we wouldn’t be receiving all the orchestration benefits as such and no reproducibility or any of the aforementioned guarantees can be ensured at the Airflow end. In a nutshell, the fundamental missing piece in this scenario is fine-grained machine learning orchestration.
Imagine a scenario where machine learning engineers are brought into an existing Airflow project that has been set up by data engineers. There is often such a big gap in terminology, conceptual approaches, and lack of understanding of the work efforts of each team because Airflow’s primarily a data-orchestration-oriented platform. To make Airflow a full-fledged machine learning orchestration service requires greater effort than usual, and might not be the right choice, after all, considering Airflow’s inclination towards ETL.
That said, Airflow can still be used to construct “static” machine learning pipelines, but if your use case is to adapt to the ever-evolving and fast-paced ecosystem around machine learning with an extreme focus on iteration (and of course, deployment), you may have to extend Airflow.
Airflow + Flyte = Maximum Flexibility
Flyte was born out of solving the challenges that Airflow presented, especially to machine learning engineers, practitioners, and data scientists. It’s a full-fledged workflow orchestration service built on top of Kubernetes to ensure the scalability of machine learning pipelines. So, why not leverage the best of both worlds — Airflow and Flyte — to scale Airflow for machine learning tasks?
Introducing Flyte Airflow Provider. You can now construct your ETL pipelines in Airflow and machine learning pipelines in Flyte and use the provider to trigger the machine learning or Flyte pipelines from within Airflow.
If you’re a long-time user of Airflow, you can approach the code piecemeal without worrying about how Airflow and Flyte intertwine together.
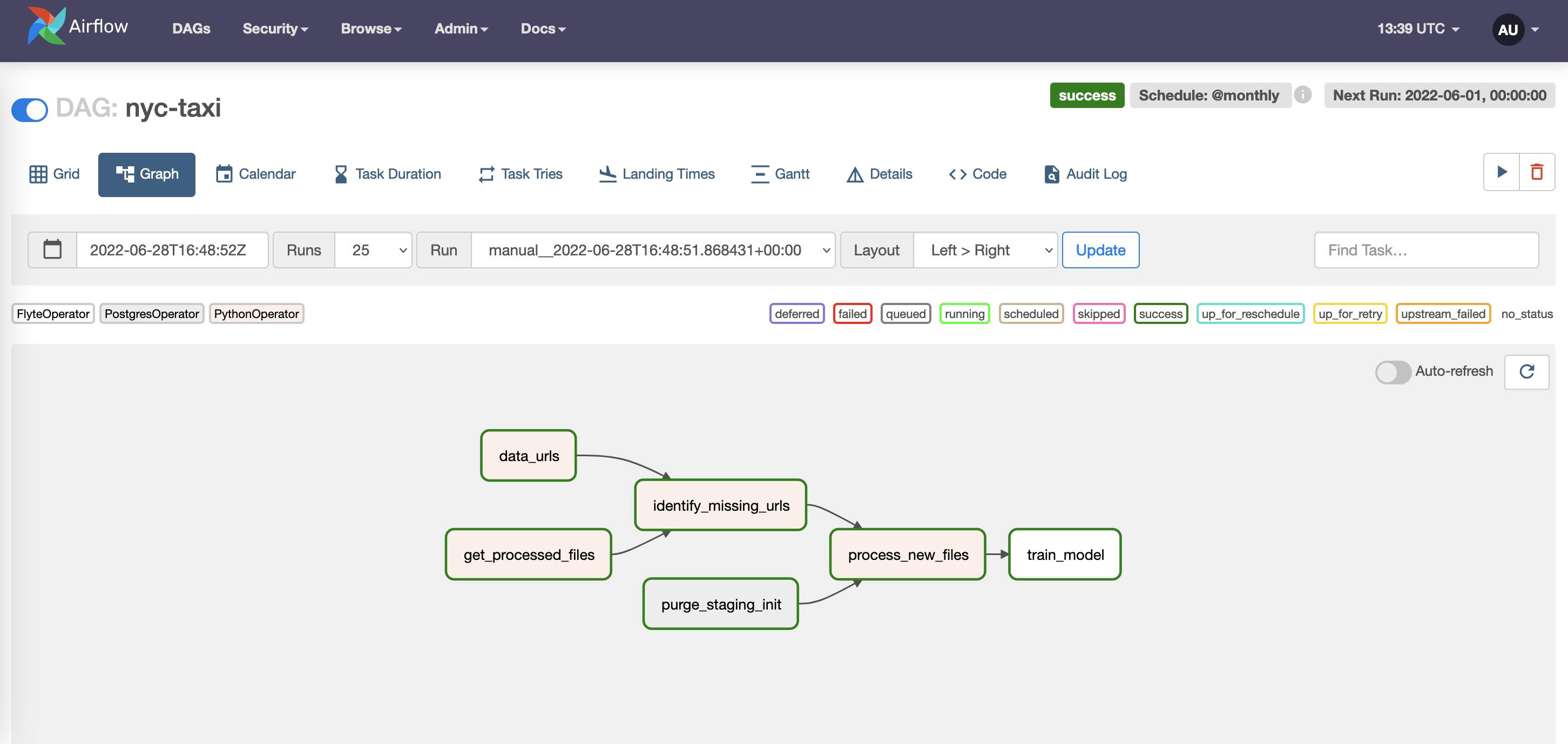 An example DAG on the Airflow UI where
An example DAG on the Airflow UI where train_model is a FlyteOperator.
Flyte Operator
You can use FlyteOperator to trigger a Flyte execution — be it a task or a workflow execution — from within Airflow, prior to which you’d have to register your Flyte workflows on the backend. On triggering the Airflow DAG, the corresponding Flyte execution gets triggered, and voila!, you’d be receiving all the benefits of Flyte within Airflow.
Flyte Sensor
If you need to wait for execution to complete, FlyteSensor comes into the picture. Monitoring with FlyteSensor allows you to trigger downstream processes only when the Flyte executions are complete.
Example
Place the following under dags/ directory after installing and setting up Airflow.
from datetime import datetime, timedelta
from airflow import DAG
from flyte_provider.operators.flyte import FlyteOperator
from flyte_provider.sensors.flyte import FlyteSensor
with DAG(
dag_id="example_flyte",
schedule_interval=None,
start_date=datetime(2021, 1, 1),
dagrun_timeout=timedelta(minutes=60),
catchup=False,
) as dag:
task = FlyteOperator(
task_id="diabetes_predictions",
flyte_conn_id="flyte_conn",
project="flytesnacks",
domain="development",
launchplan_name="ml_training.pima_diabetes.diabetes.diabetes_xgboost_model",
inputs={"test_split_ratio": 0.66, "seed": 5},
)
sensor = FlyteSensor(
task_id="sensor",
execution_name=task.output,
project="flytesnacks",
domain="development",
flyte_conn_id="flyte_conn",
)
task >> sensor
The source code of the pima_diabetes Python file is available here.
Add airflow-provider-flyte to the requirements.txt file and create an Airflow connection to Flyte by setting the Conn Id to flyte_conn and Conn Type to Flyte.
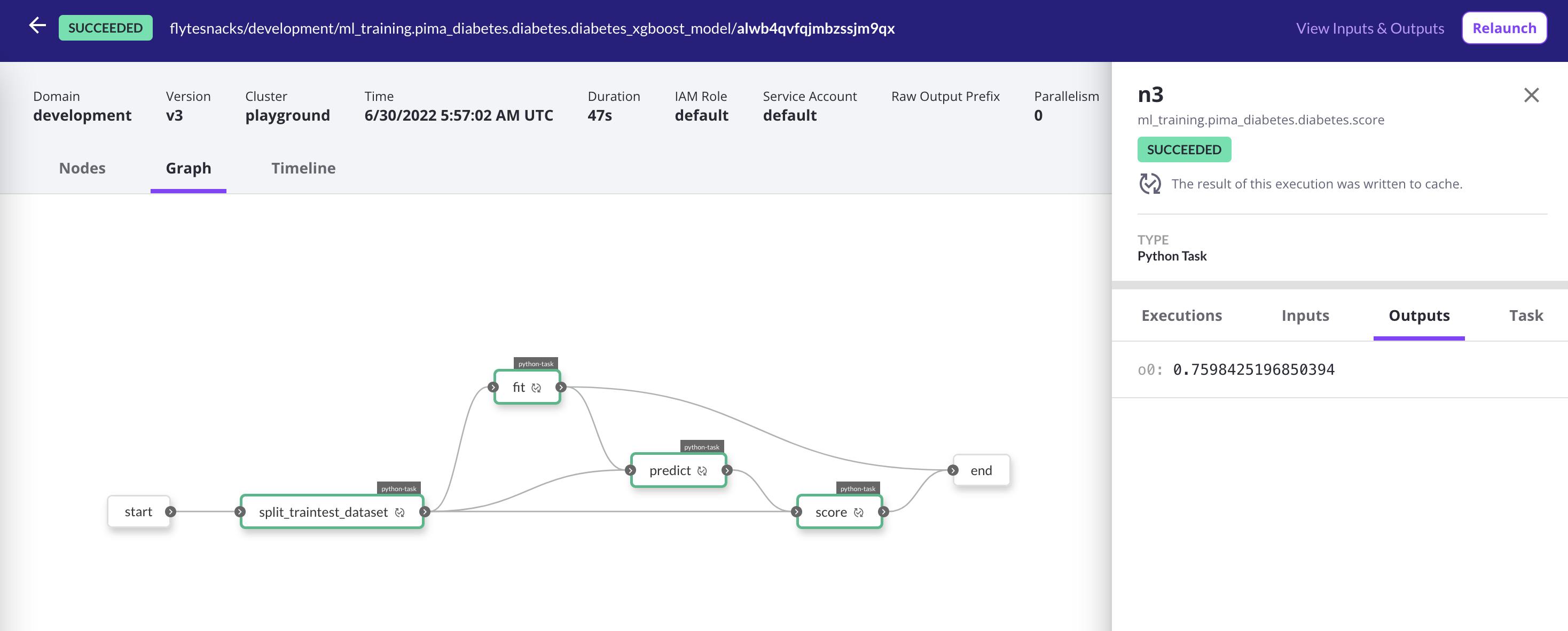 Flyte execution UI.
Flyte execution UI.
On terminating the execution either at the Airflow or Flyte end, the concerning event would be propagated to the other platform and the execution would be canceled. If the execution fails at the Flyte end, the execution at the Airflow end would fail too.
If you’d like to know a practical use case of this provider, watch this video. It demonstrates an example of pulling NYC taxi data from S3, uploading it to CrateDB, and building an XGBoost model.
Airflow is a powerful tool to run ETL pipelines; however, Airflow needs to be extended to run machine learning pipelines.
With Flyte, you can version control your code, audit the data, reproduce executions, cache the outputs, and insert checkpoints without dwelling on the scalability of your machine learning pipelines. Give Flyte Airflow Provider a try, and share your example use case with us on Slack!